Team MIT-Princeton at the Amazon Picking Challenge 2016
This year (2016), Princeton Vision Group partnered with Team MIT for the worldwide Amazon Picking Challenge and designed a robust vision solution for our 3rd/4th place winning warehouse pick-and-place robot. The details of this vision solution are outlined in our paper. All relevant code and datasets are available for download in the links below. Update: Team MIT-Princeton wins 1st place (stow task) at the 2017 Amazon Robotics Challenge! New solution here.Multi-view Self-supervised Deep Learning for 6D Pose Estimation in the Amazon Picking Challenge (pdf, arxiv)
Warehouse automation has attracted significant interest in recent years, perhaps most visibly by the Amazon Picking Challenge (APC). Achieving a fully autonomous pick-and-place system requires a robust vision system that reliably recognizes objects and their 6D poses. However, a solution eludes the warehouse setting due to cluttered environments, self-occlusion, sensor noise, and a large variety of objects. In this paper, we present a vision system that took 3rd- and 4th- place in the stowing and picking tasks, respectively at APC 2016. Our approach leverages multi-view RGB-D data and data-driven, self-supervised learning to overcome the aforementioned difficulties. More specifically, we first segment and label multiple views of a scene with a fully convolutional neural network, and then fit pre-scanned 3D object models to the resulting segmentation to get the 6D object pose. Training a deep neural network for segmentation typically requires a large amount of training data with manual labels. We propose a self-supervised method to generate a large labeled dataset without tedious manual segmentation that could be scaled up to more object categories easily. We demonstrate that our system can reliably estimate the 6D pose of objects under a variety of scenarios.
Paper

Latest version (7 May 2017): arXiv:1609.09475 [cs.CV] or here







To appear at IEEE International Conference on Robotics and Automation (ICRA) 2017
Bibtex If you find our code or datasets useful in your work, please consider citing:
@inproceedings{zeng2016multi,
title={Multi-view Self-supervised Deep Learning for 6D Pose Estimation in the Amazon Picking Challenge},
author={Zeng, Andy and Yu, Kuan-Ting and Song, Shuran and Suo, Daniel and Walker Jr, Ed and Rodriguez,
Alberto and Xiao, Jianxiong}, booktitle={Proceedings of the IEEE International Conference on Robotics and Automation}, year={2017} }
Alberto and Xiao, Jianxiong}, booktitle={Proceedings of the IEEE International Conference on Robotics and Automation}, year={2017} }
Supplementary Video
Code
All vision system code can be found in our Github repository here.Datasets
Our paper references two datasets (both available for download): • "Shelf & Tote" Benchmark Dataset for 6D Object Pose Estimation• Automatically Labeled Object Segmentation Training Dataset C++/Matlab code used to load the data can be found in our Github repository here (see rgbd-utils). Both datasets share the same file structure, and contain APC-flavored scenes of shelf bins and totes, captured using an Intel® RealSense™ F200 RGB-D Camera. Each scene includes an entire tote or a single shelf bin, which can hold one or more APC objects in various orientations. Each scene is captured from different camera viewpoints. In particular, there 18 viewpoints for the tote and 15 viewpoints for the shelf bins. In terms of file structure, the RGB-D camera sequence for each scene is saved into a corresponding folder by its name (‘scene-0000’, ‘scene-0001’, etc.). The folder contents are as follows: scene-XXXX
• camera.info.txt - a text file that holds information about the scene and RGB-D camera. This information includes the environment (‘shelf’ or ‘tote’, bin ID if applicable), a list of objects in the scene (labeled by APC object ID), 3x3 camera intrinsics (for both the color and depth sensors), 4x4 camera extrinsics (to align the depth sensor to the color sensor), and 4x4 camera poses (camera-to-world coordinates) for each viewpoint. All matrices are saved in homogenous coordinates and in meters.
• frame-XXXXXX.color.png - a 24-bit PNG RGB color image captured from the Realsense camera.
• frame-XXXXXX.depth.png - a 16-bit PNG depth image captured from the Realsense camera, aligned to its corresponding color image. Depth is saved in deci-millimeters (10-4m). Invalid depth is set to 0. For visualization, the bits per pixel have been circularly shifted to the right by 3 bits. This frame is derived from its raw counterpart (saved in folder ‘raw’) and typically contains less information.
• raw/frame-XXXXXX.depth.png - a raw 16-bit PNG depth image captured from the Realsense camera, NOT aligned to its corresponding color image. Depth is saved in deci-millimeters (10-4m). Invalid depth is set to 0. For visualization, the bits per pixel have been circularly shifted to the right by 3 bits.
"Shelf & Tote" Benchmark Dataset
"Shelf & Tote" Benchmark Dataset Download: benchmark.zip (5.8 GB)










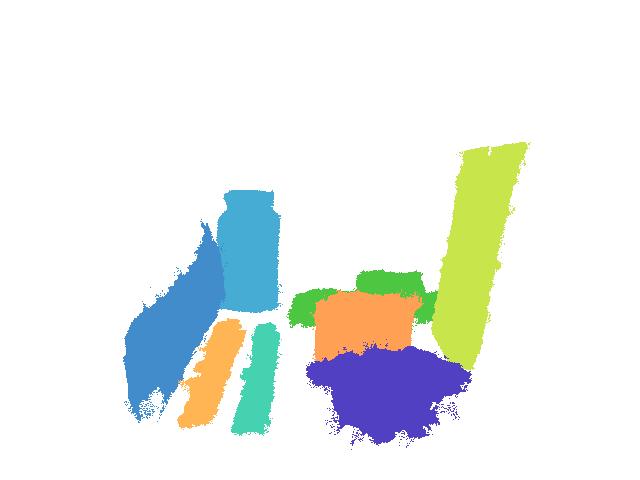





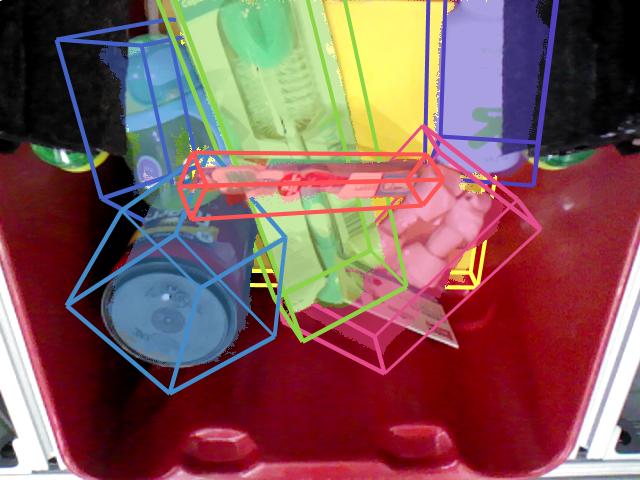





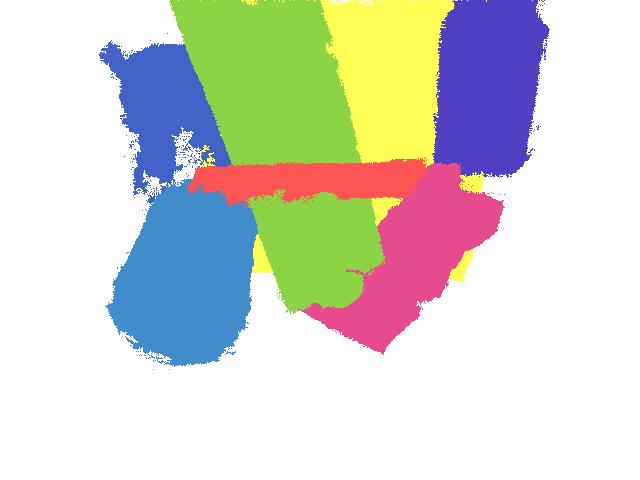











 The benchmark dataset contains 452 scenes with 2087 unique object poses seen from multiple viewpoints. In total, there are 7,281 images with manually annotated ground truth 6D object poses and segmentation labels. 266 scenes were captured in an office environment (at MIT), with strong overhead directional lights and low ambient lighting. 186 scenes were captured in a warehouse environment (at the competition location in Germany) with weak overhead directional lights and high ambient lighting. The dataset contents are divided into two main subsets:
office environment
The benchmark dataset contains 452 scenes with 2087 unique object poses seen from multiple viewpoints. In total, there are 7,281 images with manually annotated ground truth 6D object poses and segmentation labels. 266 scenes were captured in an office environment (at MIT), with strong overhead directional lights and low ambient lighting. 186 scenes were captured in a warehouse environment (at the competition location in Germany) with weak overhead directional lights and high ambient lighting. The dataset contents are divided into two main subsets:
office environment
test - 266 scenes captured in an office environment (at MIT).
calibration - a set of calibration scenes and pre-calibrated relative camera poses for the setup in the office environment. A calibration scene consists of an empty tote or shelf bin, overlaid with textured images rich with 2D features for Structure-from-Motion.
empty - a set of scenes for an empty (no object) setup in the office environment.
warehouse environment
competition - 25 scenes captured in the warehouse environment at the APC location in Germany, recorded during our final competition runs.
practice - 161 scenes captured in the warehouse environment at the APC location in Germany, recorded during our practice runs.
calibration - a set of calibration scenes and pre-calibrated relative camera poses for the setup in the warehouse environment. A calibration scene consists of an empty tote or shelf bin, overlaid with textured images rich with 2D features for Structure-from-Motion.
empty - a set of scenes for an empty (no object) setup in the warehouse environment.
Each scene (in addition to the files described here), contains:
scene-XXXX
• segm/frame-XXXXXX.segm.png - 8-bit PNG image of ground truth object segmentation labels automatically generated using the manual 6D object pose labels. Divide each pixel value by 6 to obtain label range [0,39].
Calibration Data
The camera poses of the RGB-D sequences in the dataset are retrieved from the robot’s millimeter-accurate localization software. However, small errors in camera-to-robot calibration and RGB-D camera intrinsics can cumulate to cause larger errors in the camera poses. Consequently, these errors can influence the quality of the point clouds created with multi-view reconstruction. To minimize the damage from these errors, we employ a calibration procedure that re-estimates camera poses using Structure from Motion. Each subset (office, warehouse) of the benchmark dataset contains the scenes we used for calibration (saved into a folder called 'calibration'), as well as a pre-computed set of calibrated relative camera poses for the tote (cam.pose.txt) and for each bin (cam.poses.X.txt, by bin ID). See rgbd-utils/demo.m and rgbd-utils/loadCalib.m from our Github repository for more information on how to use the calibration data.Ground Truth 6D Object Pose Labels
Information about the dataset and its ground truth labels are provided as Matlab .mat files with the following variables: scenes.mat - (scenes) 1x452 cell array of file paths to all scene directories in the dataset. labels.mat - (labels) 2087x1 cell array of ground truth object labels, each saved as a struct with the following properties:objectName - the name (aka. APC object ID) of the target object
sceneName - benchmark filepath to the scene containing the target object
objectPose - 6D pose of the target object, saved as a 4x4 object-to-world coordinate rigid transformation
occlusion - % occlusion (0 - 100) of the target object for each RGB-D frame of the scene
objects.mat - (objects) 39x1 cell array of object information, each saved as a struct with the following properties:
name the name (aka. APC object ID) of the object
isDeformable - (true/false) if the object is deformable
noDepth - (true/false) if the object has missing depth from the Realsense sensor
isThin - (true/false) if the object is thin
xSymmetry - (0,90,180,360) describing the symmetry around the pre-scanned object model's x-axis
ySymmetry - (0,90,180,360) describing the symmetry around the pre-scanned object model's y-axis
zSymmetry - (0,90,180,360) describing the symmetry around the pre-scanned object model's z-axis
Notes on object symmetry labels: a value of 0 indicates that the object model has no geometric symmetry when rotating around its specific axis. A value of 90 indicates that the object model is geometrically similar when rotated 90 degrees around its specific axis. Likewise, a value of 180 indicates that the object model is geometrically similar when rotated 180 degrees around its specific axis. A value of 360 indicates that the object model is radially symmetric around its specific axis. The pre-scanned object models for all 39 APC objects can be downloaded from our Github repository here (see ros-packages/catkin_ws/src/pose_estimation/src/models/objects).
Code used to evaluate against the ground truth labels can be found in our Github repository here (see evaluation).
Object Segmentation Training Dataset
Full Training Dataset Download: training.zip (131.4 GB) If you just want to try out a small portion of the data, you can download the sampler below: Sampler Download: training-sample.zip (93.5 MB)



























 The object segmentation training dataset contains 136,575 RGB-D images of single objects (from the APC) in the shelf and tote. There are a total of 8,181 unique poses of 39 objects seen from various camera viewpoints. All images are labeled with binary foreground object masks, which were automatically generated to train the self-supervised deep models for 2D object segmentation. Details of the automatic labeling algorithm can be found in the paper. The training dataset also contains HHA maps (Gupta et al.), pre-computed from the depth images.
Each scene (in addition to the files described here), contains:
scene-XXXX
The object segmentation training dataset contains 136,575 RGB-D images of single objects (from the APC) in the shelf and tote. There are a total of 8,181 unique poses of 39 objects seen from various camera viewpoints. All images are labeled with binary foreground object masks, which were automatically generated to train the self-supervised deep models for 2D object segmentation. Details of the automatic labeling algorithm can be found in the paper. The training dataset also contains HHA maps (Gupta et al.), pre-computed from the depth images.
Each scene (in addition to the files described here), contains:
scene-XXXX
• HHA/frame-XXXXXX.HHA.png - a 24-bit PNG of HHA maps, an encoding of every aligned depth image into three channels at each pixel: horizontal disparity, height above ground, and the angle between the surface normal and the inferred gravity direction (Gupta et al.). All channels are linearly scaled to the 0 - 255 range.
• masks/frame-XXXXXX.mask.png - an 8-bit PNG binary image of the foreground object mask for each RGB-D frame.
Contact
If you have any questions, feel free to contact me at andyz[at]princeton[dot]edu
Page last updated: 09/29/16Posted by: Andy Zeng